
3个现实生活应用程序,用于Grafana的Redis数据源

简单地说,我们现在是Redis
RedisTimeSeries是一个Redis模块,为Redis带来了原生的时间序列数据结构。时间序列解决方案早先构建在排序集(或Redis流)之上,可以受益于RedisTimeSeries的特性,如高容量插入、低延迟读取、灵活的查询语言、降采样等等!
一般来说,时间序列数据(相对)简单。说了这么多,我们需要的其他特性的因素,以及:
因此,像RedisTimeSeries这样的数据库只是整个解决方案的一部分。你还需要考虑如何去做搜集(摄入),过程,和发送所有的数据到RedisTimeSeries。您真正需要的是一个可伸缩的数据管道,它可以充当缓冲区,将生产者和消费者分离开来。
这就是Apache卡夫卡进来!除了核心代理,它还有一个丰富的组件生态系统,包括卡夫卡连接(这是本文提出的解决方案体系结构的一部分),多种语言的客户端库,卡夫卡流、制镜师等。

这篇博文提供了一个如何使用RedisTimeSeries和Apache Kafka来分析时间序列数据的实际例子。
代码可以在这个GitHub库https://github.com/abhirockzz/redis-timeseries-kafka
让我们先探讨使用情况下开始。请注意,它一直保持简单的博客文章的目的,然后在后面的章节中进一步解释。
试想一下,有很多地方,他们每个人都有多台设备,以及你与专责监控设备的指标,现在我们将考虑温度和压力。这些指标将被存储在RedisTimeSeries(当然!)并使用以下命名约定键 -<指标名称>:<位置>:<设备>.例如,位置5的设备1的温度将表示为temp:5:1。每个时间序列数据点还将具有以下内容标签(键-值对)度量,位置,设备.这是为了允许灵活的查询,你将在即将到来的部分看到。
这里有几个示例,让您了解如何使用TS.ADD.命令:
3号位置设备2的温度及标签:
TS.ADD TEMP:3:2 * 20标签度量临时定位3器件2
#在位置3为压力装置2:
TS.ADD压力:3:2 * 60标签公制压力位置3装置2
这是解决方案在高级的情况下的样子:
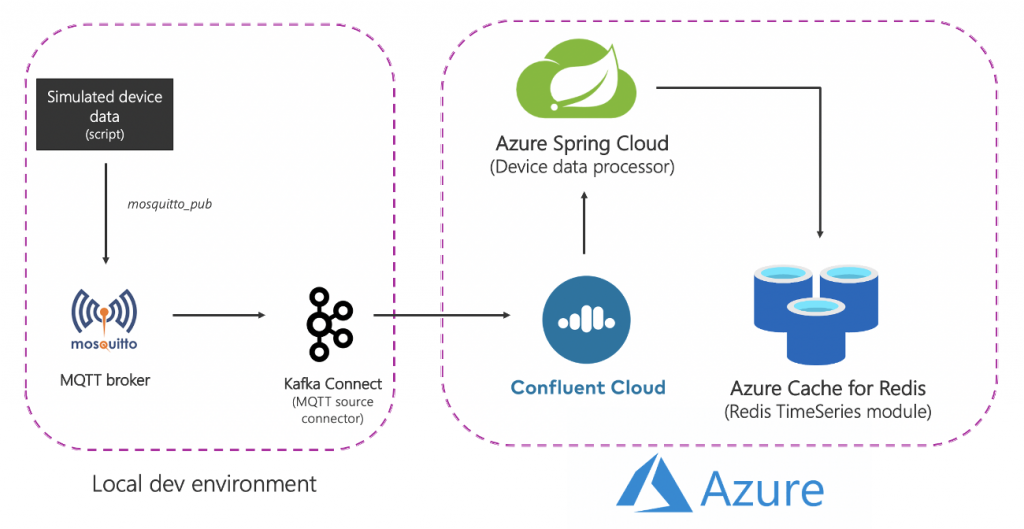
让我们打破:
源(本地)组件
Azure服务
请注意,为了简单起见,有些服务是本地托管的。在生产级部署中,您也希望在Azure中运行它们。例如,你可以在Azure Kubernetes Service中操作Kafka Connect集群和MQTT连接器。
总结一下,这是端到端流程:
是时候开始用实用的东西了!在此之前,请确保您有以下操作。
遵循文件提供Azure的缓存Redis的(企业级)它是由RedisTimeSeries模块提供的。
条款Azure Marketplace上的Confluent云集群.也创建一个Kafka主题(使用名称mqtt.device-stats),创建凭据(API键和秘密)您将在稍后使用稍后使用以安全地连接到群集。

您可以配置Azure Spring云的实例使用Azure门户或者使用Azure CLI:
AZ Spring-Cloud Create-N -g -l <输入位置E.g Southeastasia> 
在继续之前,请务必克隆GitHub库:
混帐克隆https://github.com/abhirockzz/redis-timeseries-kafka CD Redis的,时间序列,卡夫卡该组件包括:
我安装并启动了蚊子在本地Mac上的中间人。
酿酒安装蚊子酿酒服务启动蚊子你可以按照操作系统对应的步骤进行操作或者你可以用这个码头工人形象.
我在Mac本地安装并启动了Grafana。
冲泡安装grafana BREW服务启动grafana你可以为你的OS做同样的或随意使用这码头工人形象.
搬运工运行-d -p 3000:3000 --name = grafana -e “GF_INSTALL_PLUGINS = redis的-数据源” grafana / grafana你应该能够找到在回购的connect-distributed.properties文件刚刚克隆。对于如bootstrap.servers,sasl.jaas.config等属性替换的值
首先,下载并解压Apache Kafka本地。
启动本地Kafka Connect集群:
export KAFKA_INSTALL_DIR= $KAFKA_INSTALL_DIR/bin/connect-distributed.sh connect-distributed.properties 如果您正在本地使用Confluent平台,只需使用Confluent Hub CLI:confluent-hub安装最新confluentinc / kafka-connect-mqtt:
创建MQTT源连接器实例
一定要检查一下MQTT - 源config.json文件。确保输入正确的主题,可kafka.topic和离开mqtt.topics不变。
curl -X POST -H 'Content-Type: application/json' http://localhost:8083/connectors -d @mqtt-source-config. xml在检查连接器状态curl http://localhost:8083/connectors/mqtt-source/status之前,等待一分钟在你刚克隆的GitHub repo中,寻找application.yaml文件中的消费者/ src /资源文件夹并替换以下的值:
构建应用程序JAR文件:
CD消费者出口JAVA_HOME = <例如输入绝对路径/Library/Java/JavaVirtualMachines/zulu-11.jdk/Contents/Home> MVN清洁包创建一个Azure Spring云应用程序,并将JAR文件部署到其中:
az spring-cloud应用程序创建- n device-data-processor - s <春天Azure云实例名称> - g <资源组名称>——运行时版本Java_11 az spring-cloud应用部署- n device-data-processor - s <春天Azure云实例名称> - g <资源组名称>——目标/ device-data-processor-0.0.1-SNAPSHOT.jar jar路径你可以使用你刚克隆的GitHub repo中的脚本:
。/ gen-timeseries-data.sh注意,它是所有使用mosquitto_pubCLI命令发送数据。
数据被发送到设备统计数据MQTT主题(这是不卡夫卡的话题)。您可以使用CLI订户进行双重检查:
mosquito - sub -h localhost -t device-stats检查汇合云门户卡夫卡的话题。你也应该检查日志在春季天青云的装置数据处理器的应用:
az Spring - Cloud app logs -f -n device-data-processor -s < Azure Spring Cloud实例的名称> -g <资源组>的名称浏览到Grafana的UIlocalhost: 3000.
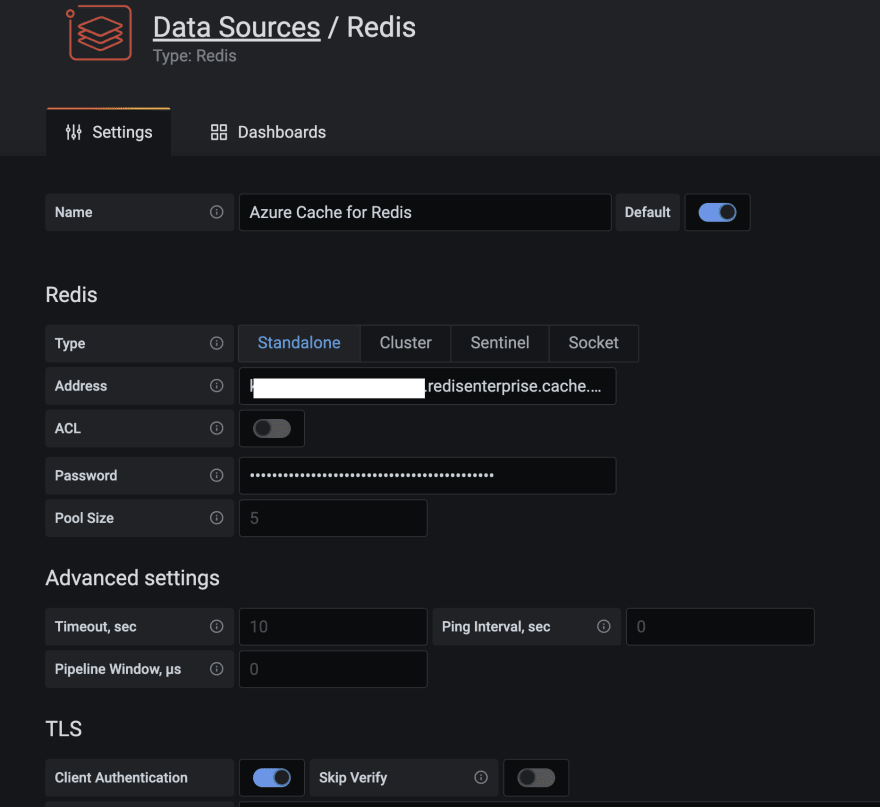
Grafana的Redis Data Source插件可以与任何Redis数据库一起工作,包括Redis的Azure Cache。遵循在这篇博客文章的说明配置数据源。
导入github repo中的grafana_dashboards文件夹中的仪表板(参见)Grafana文档如果您需要关于如何导入仪表盘援助)。
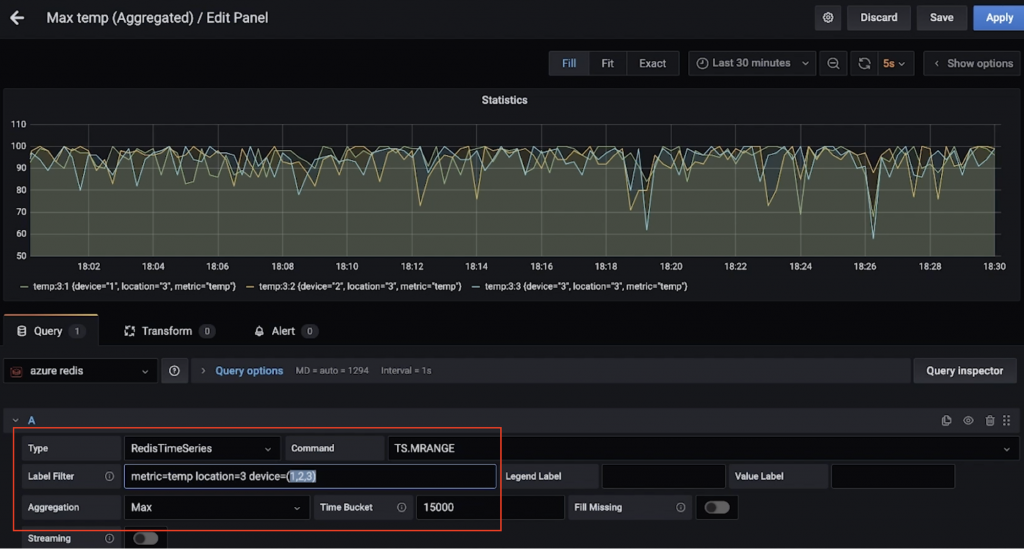
例如,这里是一个仪表板,显示的平均压力(超过30秒)为设备5在位置1(用途TS.MRANGE)。

这里是另一个仪表板,显示了多个设备的最高温度(超过15秒)位置3(再次,感谢Ts.mrange)。
卷起了redis-cli并连接到Azure缓存的Redis实例:
redis-cli -h -p 10000 -a ——tls 先从简单的查询:
#压力在装置5为位置1 TS.GET压力:1:5#温度在装置5的位置4 TS.GET温度:4:5按位置并获得温度和压力过滤器全部设备:
TS.MGET WITHLABELS FILTER位置= 3在特定时间范围内的一个或多个位置中的所有设备的温度和压力提取:
TS.MRANGE - + WITHLABELS FILTER位置= 3 TS.MRANGE - + WITHLABELS FILTER位置=(3,5)- +指的是一切从开始直到最新时间戳,但你能更具体。
MRANGE正是我们所需要的!我们还可以在某个位置使用特定的设备进行过滤,并根据温度或压力进一步下钻:
TS.MRANGE - + WITHLABELS过滤位置=3 device=2 metric=temp所有这些都可以与聚合组合。
#所有的临时数据点都没有用。用平均值(或最大值)代替每个临时数据点怎么样?TS.MRANGE - + WITHLABELS AGGREGATION max 10000过滤位置=3 metric=temp它也可以创建一个规则来做到这一点的聚集,并将其存储在不同的时间序列。
一旦完成,不要忘记删除资源以避免不必要的成本。
在您的本地机器上:
我们探索了数据管道使用Redis的和卡夫卡采集,处理和查询时间序列数据。当你想到接下来的步骤和向生产级解决方案的举动,你应该考虑一些事情。
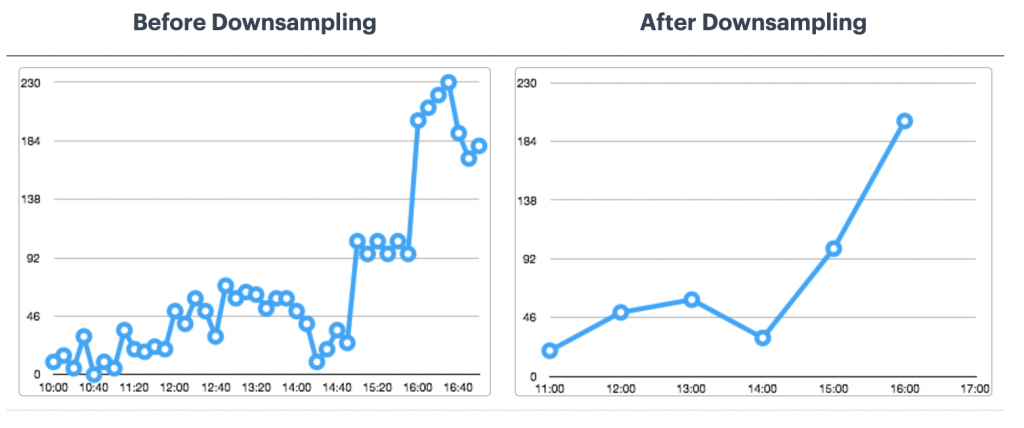
优化RedisTimeSeries
这不是一个详尽的清单。有关其他配置选项,请参阅RedisTimeSeries文档
数据是宝贵的,包括时间序列!您可能需要进一步处理它(例如运行机器学习提取洞察,预测性维护等)。为了使这成为可能,你需要保留这些数据更长的时间框架,并为此具有成本效益和效率,你会希望使用一个可扩展的对象存储服务,例如Azure数据湖存储Gen2(第二代ADLS)。

有一个连接器!您可以通过使用完全托管的数据管道来增强现有的数据管道用于融合云的Azure数据湖存储Gen2 Sink连接器处理和存储ADL中的数据,然后运行机器学习Azure突触分析或者Azure的Databricks.
可扩展性
您的时间序列数据量只能向上移动一个方向!解决方案的可扩展性至关重要:
一体化不只是格拉瓦纳!RedisTimeSeries还集成了普罗米修斯和克拉夫.然而,在这篇博客中的时间没有卡夫卡写的连接器,这将是一个伟大的附加!

当然,您可以使用REDIS(几乎)所有内容,包括时间序列工作负载!一定要考虑数据流水线的端到端架构和从时序数据源的集成,一直到Redis及更远的方式。


![]() 万博app手机客户端下载
万博app手机客户端下载